file1.txt + file2.txt + file3.txt => file123.pdf
I created this new xtopdf app recently. (For those unfamiliar with it, xtopdf (source here) is my open source Python project for PDF generation from other formats and sources. Here is a good high-level overview of xtopdf, describing what it is and can do, its supported input formats, platforms (Windows, Linux, Mac OS X, Unix) and environments (CLI, GUI, Web), etc. The core of the xtopdf project is a library, and what I call xtopdf apps, are applications built using that library.)
This particular app lets you batch-convert multiple text files at a time, to a PDF file. The content of each text file starts on a new page in the PDF file. The program uses xtopdf (which uses ReportLab) and the fileinput module from Python's standard library. The program could be written without using the fileinput module too, and I've done a variant of it that way earlier, but I used fileinput this time for convenience, and to show a use of it.
(BTW, fileinput is a pretty useful module in its own right, for this sort of work - applying the same process (any process, not just PDF generation) to a bunch of input files. fileinput can also read from standard input if no input filenames are specified, but I don't use that feature here. Also, I used 4 functions from the fileinput module, on 4 consecutive lines, in this short program :) - not just for the sake of it, though; it made sense to do so.)
Here is the code, in file BatchTextToPDF.py:
from __future__ import print_function
# BatchTextToPDF.py
# Convert a batch of text files to a single PDF.
# Each text file's content starts on a new page in the PDF file.
# Requires:
# - xtopdf: https://bitbucket.org/vasudevram/xtopdf
# - ReportLab: https://www.reportlab.com/ftp/reportlab-1.21.1.tar.gz
# Author: Vasudev Ram
# Copyright 2016 Vasudev Ram
# Product store: https://gumroad.com/vasudevram
# Web site: https://vasudevram.github.io
# Blog: http://jugad2.blogspot.com
import sys
import fileinput
from PDFWriter import PDFWriter
def usage(prog_name):
sys.stderr.write("Usage: {} outfile.pdf infile1.txt ...".format(prog_name))
def main():
if len(sys.argv) < 3:
usage(sys.argv[0])
sys.exit(0)
try:
pw = PDFWriter(sys.argv[1])
pw.setFont('Courier', 12)
pw.setFooter('xtopdf: https://google.com/search?q=xtopdf')
for line in fileinput.input(sys.argv[2:]):
if fileinput.filelineno() == 1:
pw.setHeader(fileinput.filename())
if fileinput.lineno() != 1:
pw.savePage()
pw.writeLine(line.strip('\n'))
pw.savePage()
pw.close()
except Exception as e:
print("Caught Exception: type: {}, message: {}".format(\
e.__class__, str(e)))
if __name__ == '__main__':
main()
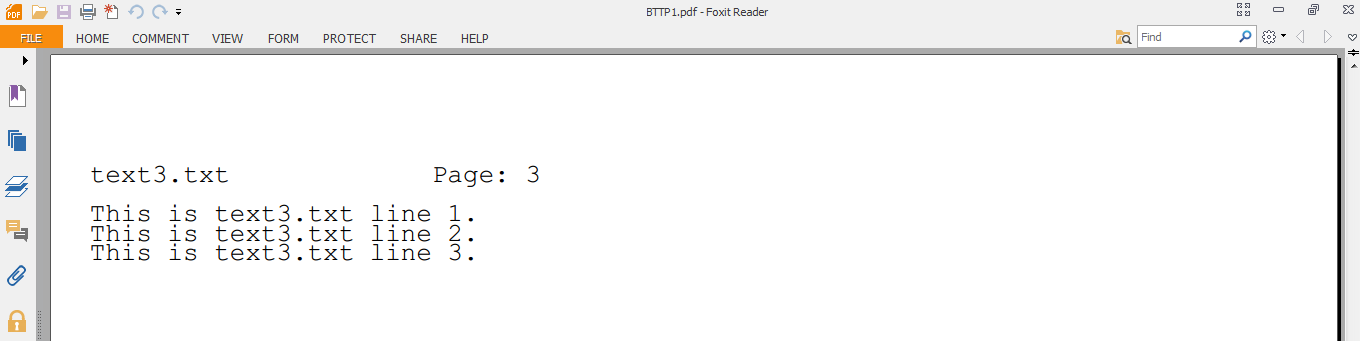
Here is a sample run of the program. I created 3 text files, text1.txt through text3.txt, with the respective number of lines in them. Then ran the command:python BTTP123.pdf text1.txt text2.txt text3.txtThis created the PDF file BTTP123.pdf. Cropped screenshots of the 1st and 3rd (last) page of the PDF are below:
1st page:
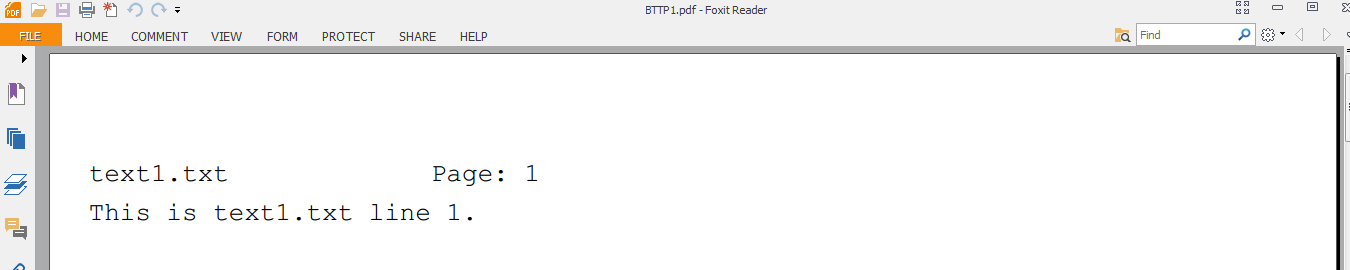
3rd page:
In this example I've closed the PDFWriter instance manually, using pw.close(), but PDFWriter can also be used with the Python with statement, since I had added context manager support to PDFWriter earlier. I use the with statement in some of my xtopdf app examples, and not in others, to show that both possibilities exist.
Here is a Guide to installing and using xtopdf, including creating simple PDF e-books with it.
- Enjoy.
- Vasudev Ram - Online Python training and consulting Get updates on my software products / ebooks / courses. Jump to posts: Python DLang xtopdf Subscribe to my blog by email My ActiveState recipes FlyWheel - Managed WordPress Hosting

No comments:
Post a Comment