
Here is another in my series of posts about xtopdf, my Python toolkit for PDF creation from other data/file formats. This one is for conversion of DSV data to PDF.
DSV stands for Delimiter-Separated Values, and is a superset or generalization of formats like CSV (Comma-Separated Values) and TSV (Tab-Separated Values). These formats are commonly used in general computing (business, scientific, etc.) and also in data science.
This program, DSVToPDF.py, builds upon the code in the read_dsv.py program in this recent post:
Processing DSV data (Delimiter-Separated Values) with Python
It reads DSV content either from filenames given as command-line arguments, or from standard input, and converts each such input into a PDF file with the same name as the DSV file, but with added extension ".pdf". In the case of standard input, since there is no DSV filename to use as the base, the PDF file is named dsv_output.pdf.
Here is the code for DSVToPDF.py:
from __future__ import print_function
"""
DSVToPDF.py
Author: Vasudev Ram
Web site: https://vasudevram.github.io
Blog: https://jugad2.blogspot.com
Product store: https://gumroad.com/vasudevram
Twitter: https://mobile.twitter.com/vasudevram
Purpose: Show how to publish DSV data (Delimiter-Separated Values)
to PDF, using the xtopdf toolkit.
Requires:
- ReportLab: https://www.reportlab.com/ftp/reportlab-1.21.1.tar.gz
- xtopdf: https://bitbucket.org/vasudevram/xtopdf
First install ReportLab, then install xtopdf, using instructions here:
http://jugad2.blogspot.in/2012/07/guide-to-installing-and-using-xtopdf.html
The DSV data can be read from either files or standard input.
The delimiter character is configurable by the user and can
be specified as either a character or its ASCII code.
References:
DSV format: https://en.wikipedia.org/wiki/Delimiter-separated_values
TAOUP (The Art Of Unix Programming): Data File Metaformats:
http://www.catb.org/esr/writings/taoup/html/ch05s02.html
ASCII table: http://www.asciitable.com/
"""
import sys
import string
from PDFWriter import PDFWriter
def err_write(message):
sys.stderr.write(message)
def error_exit(message):
err_write(message)
sys.exit(1)
def usage(argv, verbose=False):
usage1 = \
"{}: publish DSV (Delimiter-Separated-Values) data to PDF.\n".format(argv[0])
usage2 = "Usage: python" + \
" {} [ -c delim_char | -n delim_code ] [ dsv_file ] ...\n".format(argv[0])
usage3 = [
"where one of either the -c or -n option must be given,\n",
"delim_char is a single ASCII delimiter character, and\n",
"delim_code is a delimiter character's ASCII code.\n",
"Text lines will be read from specified DSV file(s) or\n",
"from standard input, split on the specified delimiter\n",
"specified by either the -c or -n option, processed, and\n",
"written, formatted, to PDF files with the name dsv_file.pdf.\n",
]
usage4 = "Use the -h or --help option for a more detailed help message.\n"
err_write(usage1)
err_write(usage2)
if verbose:
'''
for line in usage3:
err_write(line)
'''
err_write(''.join(usage3))
if not verbose:
err_write(usage4)
def str_to_int(s):
try:
return int(s)
except ValueError as ve:
error_exit(repr(ve))
def valid_delimiter(delim_code):
return not invalid_delimiter(delim_code)
def invalid_delimiter(delim_code):
# Non-ASCII codes not allowed, i.e. codes outside
# the range 0 to 255.
if delim_code < 0 or delim_code > 255:
return True
# Also, don't allow some specific ASCII codes;
# add more, if it turns out they are needed.
if delim_code in (10, 13):
return True
return False
def dsv_to_pdf(dsv_fil, delim_char, pdf_filename):
with PDFWriter(pdf_filename) as pw:
pw.setFont("Courier", 12)
pw.setHeader(pdf_filename[:-4] + " => " + pdf_filename)
pw.setFooter("Generated by xtopdf: https://google.com/search?q=xtopdf")
for idx, lin in enumerate(dsv_fil):
fields = lin.split(delim_char)
assert len(fields) > 0
# Knock off the newline at the end of the last field,
# since it is the line terminator, not part of the field.
if fields[-1][-1] == '\n':
fields[-1] = fields[-1][:-1]
# Treat a blank line as a line with one field,
# an empty string (that is what split returns).
pw.writeLine(' - '.join(fields))
def main():
# Get and check validity of arguments.
sa = sys.argv
lsa = len(sa)
if lsa == 1:
usage(sa)
sys.exit(0)
elif lsa == 2:
# Allow the help option with any letter case.
if sa[1].lower() in ("-h", "--help"):
usage(sa, verbose=True)
sys.exit(0)
else:
usage(sa)
sys.exit(0)
# If we reach here, lsa is >= 3.
# Check for valid mandatory options (sic).
if not sa[1] in ("-c", "-n"):
usage(sa, verbose=True)
sys.exit(0)
# If -c option given ...
if sa[1] == "-c":
# If next token is not a single character ...
if len(sa[2]) != 1:
error_exit(
"{}: Error: -c option needs a single character after it.".format(sa[0]))
if not sa[2] in string.printable:
error_exit(
"{}: Error: -c option needs a printable ASCII character after it.".format(\
sa[0]))
delim_char = sa[2]
# else if -n option given ...
elif sa[1] == "-n":
delim_code = str_to_int(sa[2])
if invalid_delimiter(delim_code):
error_exit(
"{}: Error: invalid delimiter code {} given for -n option.".format(\
sa[0], delim_code))
delim_char = chr(delim_code)
else:
# Checking for what should not happen ... a bit of defensive programming here.
error_exit("{}: Program error: neither -c nor -n option given.".format(sa[0]))
try:
# If no filenames given, do sys.stdin to PDF ...
if lsa == 3:
print("Converting content of standard input to PDF.")
dsv_fil = sys.stdin
dsv_to_pdf(dsv_fil, delim_char, "dsv_output.pdf")
dsv_fil.close()
print("Output is in dsv_output.pdf")
# else (filenames given), convert them to PDFs ...
else:
for dsv_filename in sa[3:]:
pdf_filename = dsv_filename + ".pdf"
print("Converting file {} to PDF.", dsv_filename)
dsv_fil = open(dsv_filename, 'r')
dsv_to_pdf(dsv_fil, delim_char, pdf_filename)
dsv_fil.close()
print("Output is in {}".format(pdf_filename))
except IOError as ioe:
error_exit("{}: Error: {}".format(sa[0], repr(ioe)))
if __name__ == '__main__':
main()
Note the commented and uncommented lines in the "if verbose:" clause in the usage() function. The latter is shorter, and, methinks, a tad more Pythonic.I did a sample run with the data shown in the image at the top of this post, which uses the pipe character (|) as the delimiter between fields (124 is the ASCII code for the pipe character):
$ python DSVToPDF.py -n 124 file4.dsvAnd here is a cropped screenshot of the PDF output as viewed in Foxit PDF Reader:
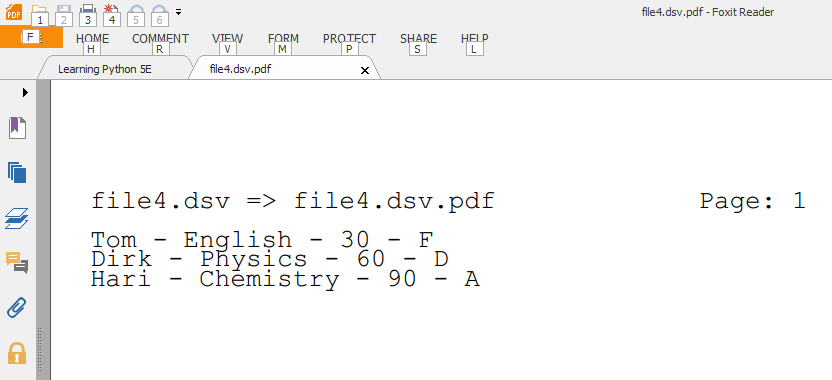
- Enjoy.
- Vasudev Ram - Online Python training and consulting Get updates on my software products / ebooks / courses. Jump to posts: Python DLang xtopdf Subscribe to my blog by email My ActiveState recipes Managed WordPress Hosting by FlyWheel

No comments:
Post a Comment